
Dirty data or unclean data is customer or business data that is faulty, meaning it contains records that are duplicates, insecure, incomplete, inaccurate, inconsistent, or have gone stale over time. Examples of dirty data include misspelled addresses, emails, outdated phone numbers, duplicate customer records or multiple records of a person’s details but are inconsistent.
Over time, dirty data will cause serious issues for businesses, including negative customer experiences, misrepresentation of business results, and poor strategic decisions that will ultimately affect their bottom line.
Examples of Dirty Data:
Duplicate Data
Duplicate data refers to multiple data sets from the same individual that partially or fully share the same information; for example, Mrs Beth Smithe from 321 Main Street, also being entered as Elizabeth Smith from 312 Main Street.
This happens from customers engaging with businesses from multiple touch points or channels and inputting different or inconsistent information.
This can cause inconsistent customer information, which can get spread across an organisation’s different departments internally, impacting a single customer view.
This then leads to a host of other problems, like multiple communication efforts to one person or misunderstanding the customer relationship. You can learn more about What is Duplicate Data.

Incomplete Data
This is a straightforward error in input data that has not been completed; for example, persons entering email addresses on a webform that may be missing letters, or addresses missing information such as postcode or street name.
Businesses may also make this mistake when forgetting to mark certain fields as required in their sign-up or checkout process. This can cause problems down the chain when trying to communicate with those customers, sending parcels or mail out to them, and simply not being able to use their data for further business activities.
Inaccurate Data
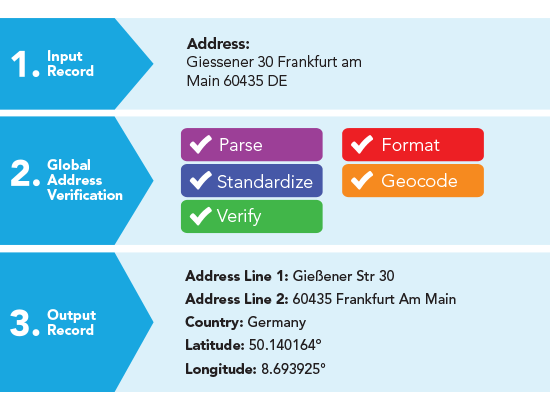
Inaccurate data can be caused by typical human error, or the source of data it came from not being referenced or certified. An example of this is when a customer enters their address during the checkout process; it may accidently be delivered to the address next door due to inaccurate data around that address, or the address not being standardised to its local country format if it’s international. Inaccurate data can be common for persons living at properties that have multiple addresses multiple residences in the same premise, and newly built premises where address data may not be verified yet. In each of these cases, we can see how address validation technology would be able to solve these common problems with ease!
If you would like to know about Address Verification, you can read our article called How does an Address Verification System Work.
Outdated Data
One core rule to remember is that customer data will go stale at a rate of 2% each month, and over 20% per year. This is due to persons moving, changing jobs, updating their phone numbers, marrying, divorcing, and dying, not to mention individuals also opting out of communication from organisations.
Businesses big or small holding a customer database should be cleansing their data regularly to avoid problems that may arise further down the track, as more of their customer records degrade over time and becomemore costly.
Businesses that implement Data cleansing get the best out of their CRM - when all records are returned clean, up to date, compliant, and with the potential for enrichment, it ensures confidence and peace of mind.
You can learn more about What is Data Cleansing

Incorrect Data
Incorrect data is data that has been entered incorrectly due to human error, such as wrong addresses entered during the checkout process, misspelled emails,, incorrect phone numbers, and other mistakes entered into data fields. Organisations can prevent human error by implementing data verification tools like address lookup during the checkout or sign-up process so only correct addresses enter their system. This can be the same for email and phone data inputs where they are pinged in real-time to ensure they are live, callable, and active.
Inconsistent data
Inconsistent data is known as data redundancy, occurring when organisations store the same customer information in different places across departments, such as in CRM software and also in an email marketing tool without syncing the information and obtaining that one single customer view. Much like having duplicate data, utilising a data duplication tool can match and deduplicate any data across an organisation’s frontier. We also recommend using data quality tools to verify and clean core contact fields like address, email and phone to filter out the dirty and/or stale data.
You can learn more about What is Data Quality.
Insecure Data
Lastly, insecure data is when organisations are holding data that may be subject to data security and data privacy laws. Rules around complying with GDPR standards are becoming more prominent and impose hefty fines when breached;this can be as simple as having the contact information of persons who did not opt-in or agree to a business storing their data and/or communicating with them.
The key to avoiding the potential consequences of breaching data privacy laws is for business to suppress their data against a list of reference data points which are refreshed on a daily bases. This can include suppressing it against goneaways, deceased, and flagging individuals that have opted out of mail and telephone communication (MPS/TPS Preference).
In essence, this can be done as part of routine data cleansing to ensure clean, up-to-date, and 100% compliant contact data.
Melissa – The Address Experts
As the leader in address verification, Melissa combines decades of experience with unmatched technology and global support to offer solutions that quickly and accurately verify addresses in real-time, at the point of entry. Melissa is a single-source vendor for address management, data hygiene and pre-sorting solutions, empowering businesses all over the world to effectively manage their data quality.