Give Yourself an Advantage These Midterms: Accurate Data
|
Midterms are right around the corner, and with redistricting efforts in many states under way, scrutiny on voter rolls and fraud, and the spread of misinformation and disinformation, it’s more crucial than ever to have complete, accurate data, updated as soon as possible. And success at the polls all starts with one thing—the data that you have behind your campaigns.
Check out some of the ways you can prepare your data to cut through the noise, find your constituents and have a successful campaign these midterms.
|
|
|
|
Better Outreach With the Best Campaign Management Tools
|
|
|
|
|
Want a quick, efficient way to maintain and update your campaign lists? Melissa Alert Service provides real-time monitoring of changes to your voters and their addresses, so your data is fresh every time you send a mail piece.
It all works without any manual oversight from you. All you have to do is create your list and set your alerts. Then, we monitor for changes, sending you a notification every time there’s an update. You can download your up-to-date list whenever you want, however many times you need.
|
|
|
|
You can create as many lists as you’d like and set specific alerts to each one, which makes Melissa Alert Service great for managing multiple campaigns. Track updates for:
|
- Change of address when people move in and out of your district.
- Address updates like street number or ZIP Code changes.
- Property transactions, including change of ownership.
- Deceased, so you can maintain constituent respect.
|
|
|
|
|
Hyper-Accurate District Data With the Best Address-to-District Matching
|
|
|
|
Along with Melissa Alert Service, you can run your lists through our government-specific Cicero solution to enhance your data with correct district codes and comprehensive elected official data. This is more important than ever with the redistricting push that’s happening.
Redistricting makes old district assignments obsolete, and your old ZIP Codes and voter file district tags are no longer reliable once those maps go into effect. We monitor for all off-cycle changes and update accordingly so you always have the most accurate data when outreaching to voters.
|
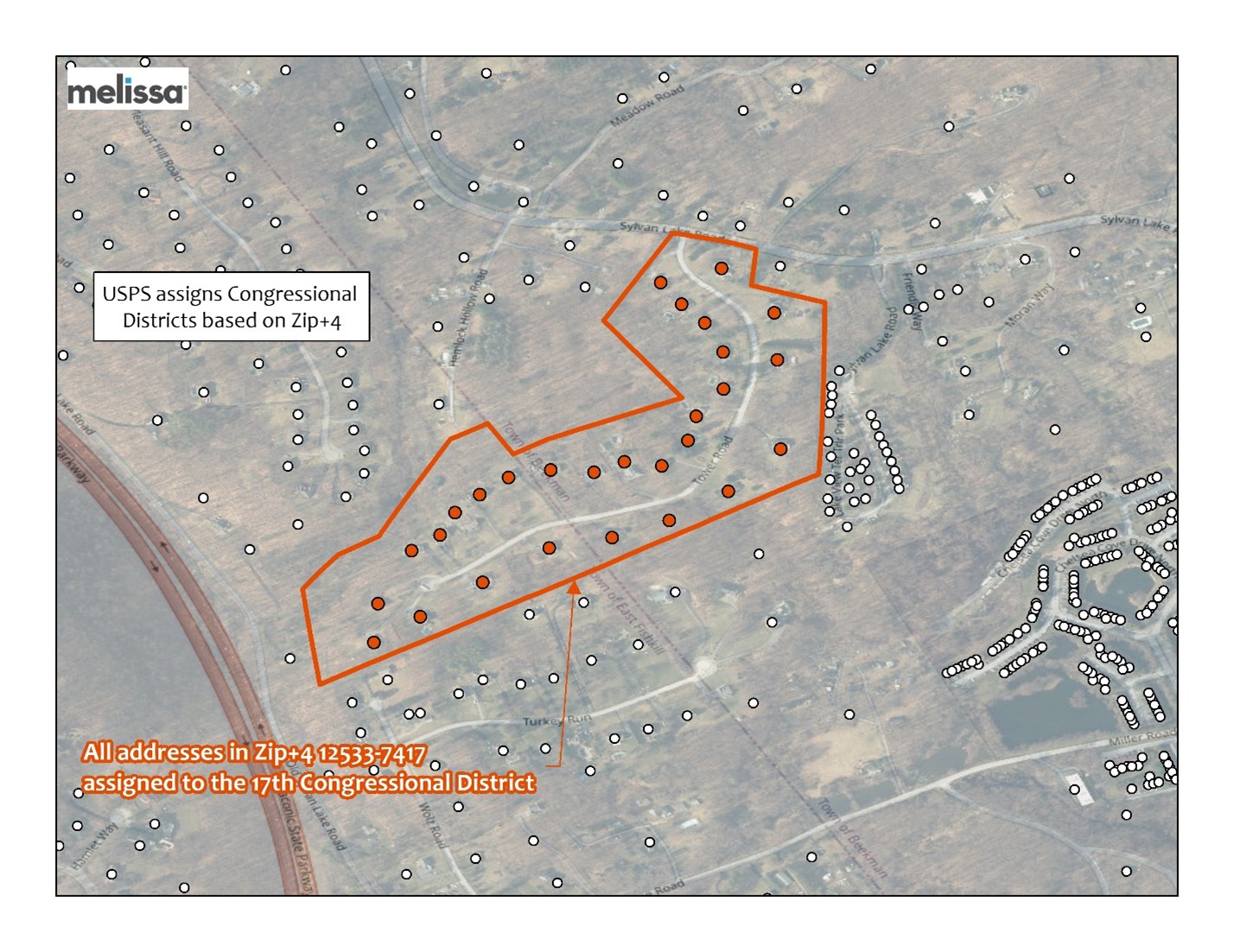
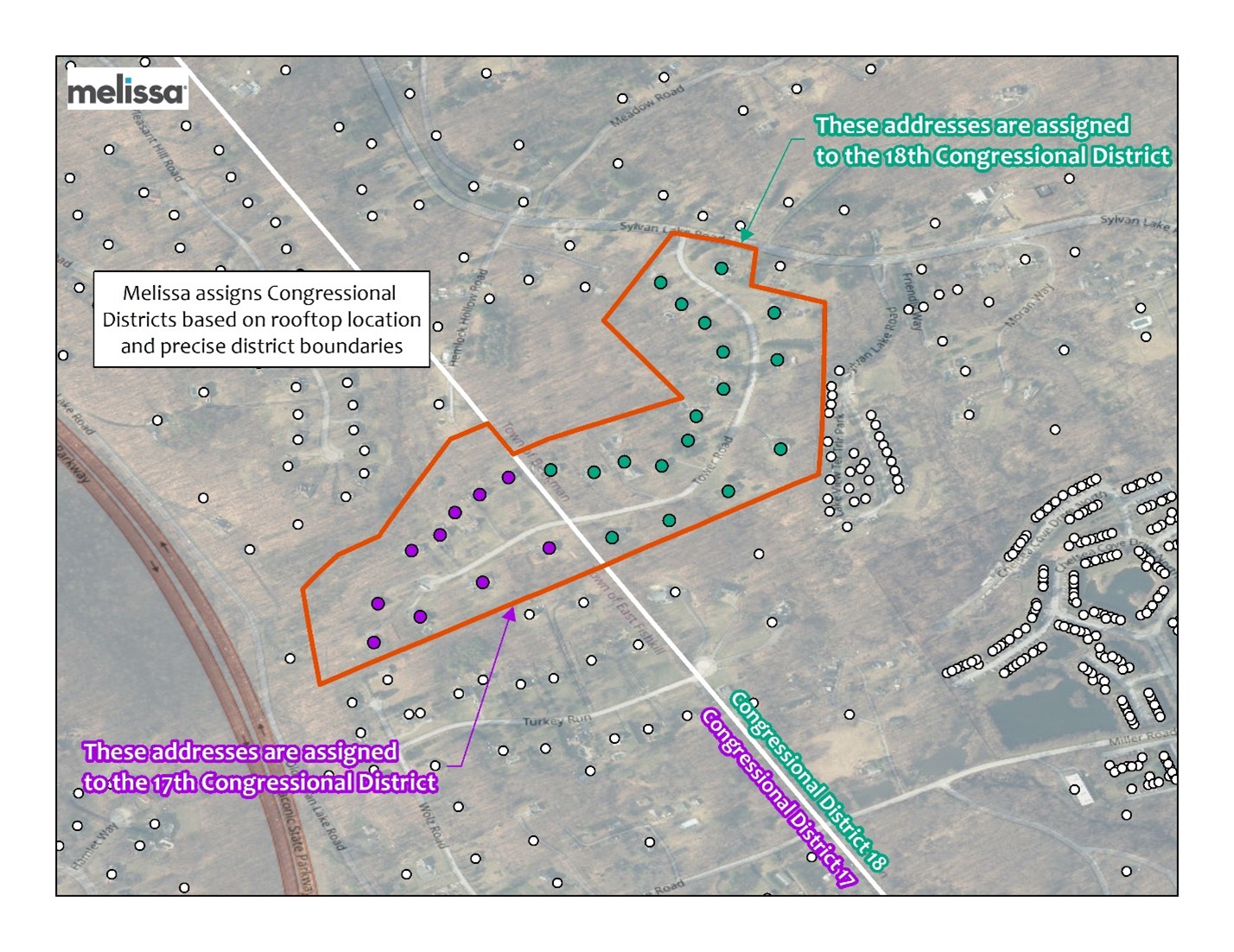
Plus, unlike other providers who use ZIP or ZIP+4 to determine voting districts, we use hyper-accurate address-to-district matching. This means we convert street addresses to precise latitude and longitude coordinates using rooftop geocoding and point-in-polygon matching against official, high-resolution district boundary files, updated daily.
|
|
|
|
The Best Data Quality with Our Full Service Bureau
|
We know how busy you and your staff are, especially during an election year. If you want us to handle any or all of your data cleansing needs for you, we’re more than happy to help! Our full service bureau will clean, standardize, enhance and update all of your data with tools such as:
|
- National change-of-address to add and remove movers who have recently entered or left your district.
- District matching so you can determine which voters and addresses belong in your district.
- Deceased suppression to maintain voter roll integrity.
- Email and phone append so you can have updated contact information for multi-channel messaging.
|
All of Melissa’s tools for government are flexible and customizable to fit your specific campaign needs. We’re here to help you have the most successful midterm elections you can, and that starts with clean data.
|
|
|
|
|
|
Think differently about your data with our new podcast, What’s In Your Data? New episodes drop every other week, so make sure to subscribe so you don’t miss out!
|
|
|
|
|